


学生团队自主研发古文翻译“神器”
2017年10月11日
文言文看不懂怎么办?如何更轻松地学习古文?今年暑假,西交利物浦大学的研究生吴海旭(下图左)和两名本科学生陈军(下图右)、叶啸东组成了科研团队,他们在计算机科学与软件工程系张百灵博士的指导下共同研发了一个古文翻译“神器,该软件可以将输入的文言文自动翻译成白话文,方便读者更快速地理解古文。

吴海旭本科毕业于宁波诺丁汉大学,目前在西浦计算机科学专业攻读研究生,他说:“虽然我本科和研究生都是在中外合办的国际大学读的,但我对古文的热爱依旧没有减少。”
理科生始终保持对古文的热爱
吴海旭虽然学习的是理科专业,但他一直保持着一颗热爱中国传统文化和古文的心。在为毕业设计做准备时,他突然想到能否把自己的专业领域和古文结合起来,用人工智能技术对古文进行处理,让理解古文变得更方便简单。
他回忆说,最初的想法是做文言文到句读的转换,后来经过思考觉得不如直接做文言文到现代汉语的翻译。于是,做古文翻译软件的想法就在吴海旭的脑海里萌生了。
吴海旭把这个点子告诉了张百灵老师,张老师对此表示十分支持,“这样的研究在学术界是前所未有的,不管他最后能否把这个软件做好,这个想法都是很值得鼓励的,因为科研的结果并不重要,重要的是学生在过程中的学习和提升。”

在张老师的鼓励和建议下,吴海旭参加了学校的夏季本科生研究基金项目(SURF),并在老师的介绍下认识了计算机科学与技术专业的大四学生陈军和电气工程及其自动化专业的大二学生叶啸东。
三个学生组成了一个团队,在简单的开会讨论明确研究方向后,大家就将这个想法开始付诸行动了。
从零开始 挑战未知
吴海旭从今年三月就开始为这项研究做准备,陈军和叶啸东(下图)在忙完了其他项目之后也马不停蹄地加入进来。由于他们面临的是一项全新的技术,所以前期准备的大部分时间都用来重新学习相关知识。

“深度学习和自然语言处理是我从来没接触过的知识,所以这个项目对我来说也是一个很大的挑战。” 吴海旭说,他们一方面需要学习深度学习框架,一方面还要学习自然语言中翻译的部分,同时也需要阅读大量一些关于翻译的技术和算法的论文,看看前沿的研究成果是怎样的。
准备阶段过后,他们就开始着手整个项目中最困难的部分——收集数据。为了解决因数据不足而产生的翻译效果不理想的核心问题,他们参考了一篇题为《用于机器翻译的对偶学习》的论文,并尝试使用论文中提到的对偶式学习算法:以单一语料库为主、平行语料库为辅来训练数据。
仅仅收据数据这个过程就花了他们一个月的时间,但经过试验后发现模型的效果仍然不能达到预期。这是吴海旭没想到的,“本来我们在用这个算法做数据的时候是信心满满的,觉得一定可以成功,但最后的结果却让大家的心情瞬间跌入谷底。”
学术界古文翻译软件的先行者
这一次小小的挫折并没有让团队三人停止前进的脚步。经过缜密的分析与研究,他们发现,导致翻译效果不好的真正原因在于这些数据需要被“改造”,从网上收集的由古文翻译来的现代汉语中存在很严重的意译现象,这会在深度学习中产生大量的噪音,导致模型不佳。
在讨论解决方案时,三人产生了分歧。吴海旭认为应该把数据先经过技术处理再人工改成直译,而叶啸东觉得这样做会耗费太多时间,他提出用增大数据量的方法来减少噪音,但吴海旭并不同意这个做法,理由是噪音的比例是一定的,数据量增大可能不会使噪音减少。
最后通过多次反复的试验证实了吴海旭的猜想,于是三人进一步明确分工,陈军和叶啸东负责收集数据,再交给吴海旭进行改直译的处理。
在三人日以继夜的努力下,这款翻译软件终于被做成了,而且相关论文的初稿也已完成,未来有望在国际期刊上发表。
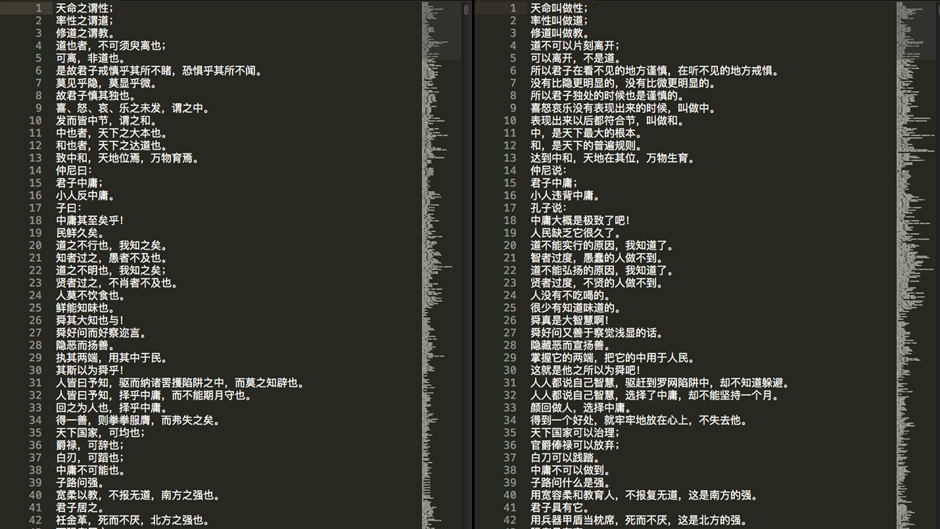
“虽然在商业领域中百度翻译已经有古文翻译的产品了,但我们在学术界还是最早一批,能做一个学术先锋,这让我们都感到十分自豪。”陈军激动地说,“这也是我第一次参与正式的科研项目,最重要的并不是我们的成果,而是在这个过程中学到的新的知识和技术,以及不断尝试新东西的精神。”
对于接下来的计划,吴海旭说,“希望有机会可以在词嵌入和专有名词识别方面对软件进行改进,使软件的翻译效果更准确。”
张百灵博士对此也寄予厚望,希望这个项目可以被保留为学校层面的一个科研项目,在未来吸引更多感兴趣的学生加入,使得这项研究继续深入下去。
(记者:付雅琪 编辑:许恬甜)
2017年10月11日


